



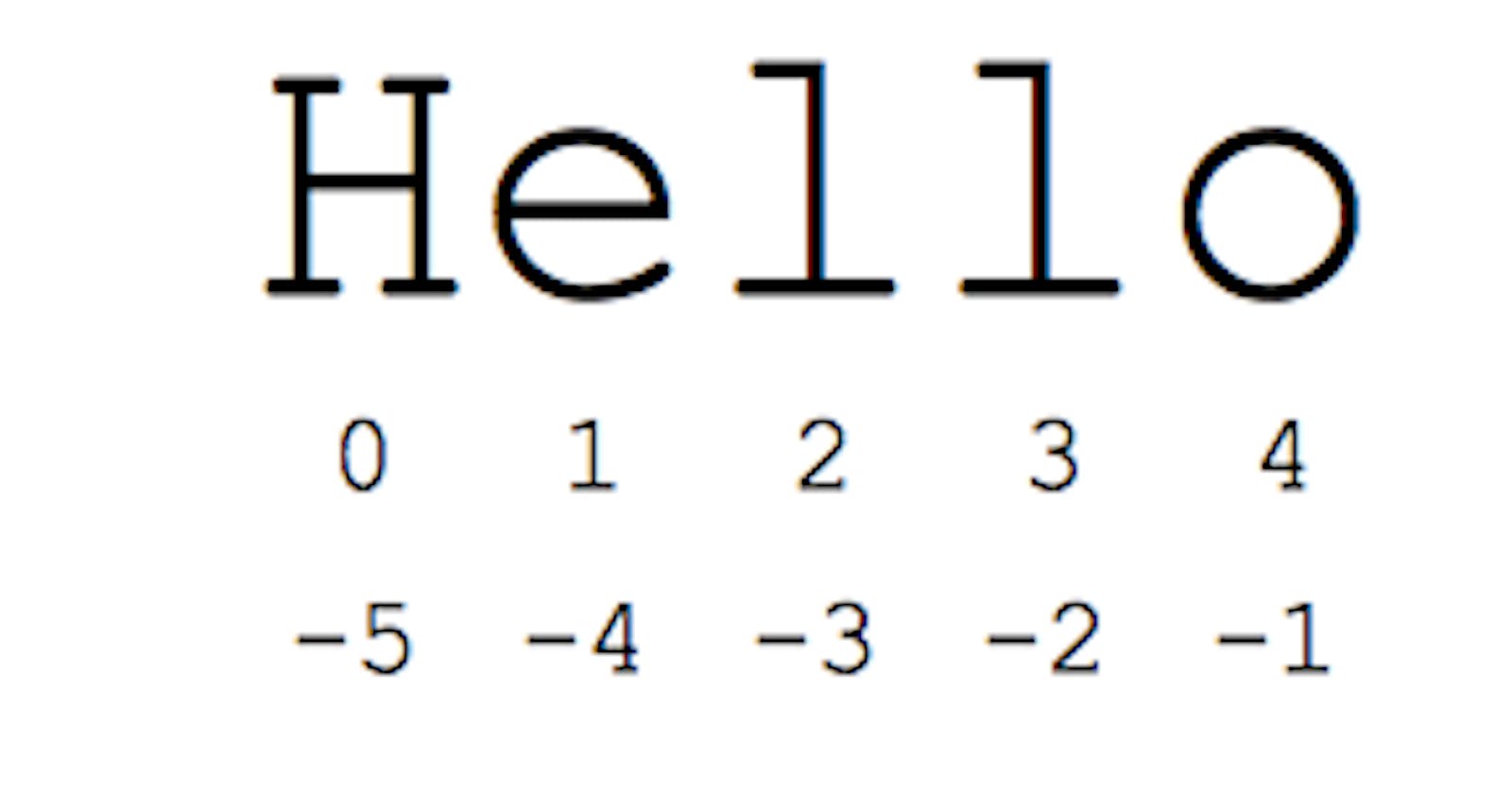
Strings are arrays of bytes representing Unicode characters. However, Python does not have a character data type, a single character is simply a string with a length of 1. Square brackets can be used to access elements of the string.
# Python Program for
# Creation of String
# Creating a String
# with single Quotes
String1 = 'Welcome to the Geeks World'
print("String with the use of Single Quotes: ")
print(String1)
# Creating a String
# with double Quotes
String1 = "I'm a Geek"
print("\nString with the use of Double Quotes: ")
print(String1)
# Creating a String
# with triple Quotes
String1 = '''I'm a Geek and I live in a world of "Geeks"'''
print("\nString with the use of Triple Quotes: ")
print(String1)
# Creating String with triple
# Quotes allows multiple lines
String1 = '''Geeks
For
Life'''
print("\nCreating a multiline String: ")
print(String1)
String with the use of Single Quotes:
Welcome to the Geeks World
String with the use of Double Quotes:
I'm a Geek
String with the use of Triple Quotes:
I'm a Geek and I live in a world of "Geeks"
Creating a multiline String:
Geeks
For
Life
String Slicing
To access a range of characters in the String, method of slicing is used. Slicing in a String is done by using a Slicing operator (colon).
# Python Program to
# demonstrate String slicing
# Creating a String
String1 = "GeeksForGeeks"
print("Initial String: ")
print(String1)
# Printing 3rd to 12th character
print("\nSlicing characters from 3-12: ")
print(String1[3:12])
# Printing characters between
# 3rd and 2nd last character
print("\nSlicing characters between " +
"3rd and 2nd last character: ")
print(String1[3:-2])
Initial String:
GeeksForGeeks
Slicing characters from 3-12:
ksForGeek
Slicing characters between 3rd and 2nd last character:
ksForGee
Escape Sequencing in Python
While printing Strings with single and double quotes in it causes SyntaxError because String already contains Single and Double Quotes and hence cannot be printed with the use of either of these. Hence, to print such a String either Triple Quotes are used or Escape sequences are used to print such Strings. Escape sequences start with a backslash and can be interpreted differently. If single quotes are used to represent a string, then all the single quotes present in the string must be escaped and the same is done for Double Quotes.
# Python Program for
# Escape Sequencing
# of String
# Initial String
String1 = '''I'm a "Geek"'''
print("Initial String with use of Triple Quotes: ")
print(String1)
# Escaping Single Quote
String1 = 'I\'m a "Geek"'
print("\nEscaping Single Quote: ")
print(String1)
# Escaping Double Quotes
String1 = "I'm a \"Geek\""
print("\nEscaping Double Quotes: ")
print(String1)
# Printing Paths with the
# use of Escape Sequences
String1 = "C:\\Python\\Geeks\\"
print("\nEscaping Backslashes: ")
print(String1)
Initial String with use of Triple Quotes:
I'm a "Geek"
Escaping Single Quote:
I'm a "Geek"
Escaping Double Quotes:
I'm a "Geek"
Escaping Backslashes:
C:\Python\Geeks\
# Printing Geeks in HEX
String1 = "This is \x47\x65\x65\x6b\x73 in \x48\x45\x58"
print("\nPrinting in HEX with the use of Escape Sequences: ")
print(String1)
# Using raw String to
# ignore Escape Sequences
String1 = r"This is \x47\x65\x65\x6b\x73 in \x48\x45\x58"
print("\nPrinting Raw String in HEX Format: ")
print(String1)
Printing in HEX with the use of Escape Sequences:
This is Geeks in HEX
Printing Raw String in HEX Format:
This is \x47\x65\x65\x6b\x73 in \x48\x45\x58
Formatting of Strings
Strings in Python can be formatted with the use of the format() method which is a very versatile and powerful tool for formatting Strings. Format method in String contains curly braces {} as placeholders which can hold arguments according to position or keyword to specify the order.
# Python Program for
# Formatting of Strings
# Default order
String1 = "{} {} {}".format('Geeks', 'For', 'Life')
print("Print String in default order: ")
print(String1)
# Positional Formatting
String1 = "{1} {0} {2}".format('Geeks', 'For', 'Life')
print("\nPrint String in Positional order: ")
print(String1)
# Keyword Formatting
String1 = "{l} {f} {g}".format(g = 'Geeks', f = 'For', l = 'Life')
print("\nPrint String in order of Keywords: ")
print(String1)
Print String in default order:
Geeks For Life
Print String in Positional order:
For Geeks Life
Print String in order of Keywords:
Life For Geeks
# Formatting of Integers
String1 = "{0:b}".format(16)
print("\nBinary representation of 16 is ")
print(String1)
# Formatting of Floats
String1 = "{0:e}".format(165.6458)
print("\nExponent representation of 165.6458 is ")
print(String1)
# Rounding off Integers
String1 = "{0:.2f}".format(1/6)
print("\none-sixth is : ")
print(String1)
The binary representation of 16 is
10000
Exponent representation of 165.6458 is
1.656458e+02
one-sixth is :
0.17
# String alignment
String1 = "|{:<10}|{:^10}|{:>10}|".format('Geeks','for','Geeks')
print("\nLeft, center and right alignment with Formatting: ")
print(String1)
# To demonstrate aligning of spaces
String1 = "\n{0:^16} was founded in {1:<4}!".format("GeeksforGeeks", 2009)
print(String1)
Left, center and right alignment with Formatting:
|Geeks | for | Geeks|
GeeksforGeeks was founded in 2009!
Built-in Functions
capitalize() Capitalizes first letter of string
center(width, fillchar) Returns a space-padded string with the original string centered to a total of width columns.
count(str, beg= 0,end=len(string)) Counts how many times str occurs in string or in a substring of string if starting index beg and ending index end are given.
decode(encoding='UTF-8',errors='strict') Decodes the string using the codec registered for encoding. encoding defaults to the default string encoding.
encode(encoding='UTF-8',errors='strict') Returns encoded string version of string; on error, default is to raise a ValueError unless errors is given with 'ignore' or 'replace'.
endswith(suffix, beg=0, end=len(string)) Determines if a string or a substring of string (if starting index beg and ending index end are given) ends with a suffix; returns true if so and false otherwise.
expandtabs(tabsize=8) Expands tabs in the string to multiple spaces; defaults to 8 spaces per tab if tab size not provided.
find(str, beg=0 end=len(string)) Determine if str occurs in string or in a substring of string if starting index beg and ending index end are given returns index if found and -1 otherwise.
index(str, beg=0, end=len(string)) Same as find(), but raises an exception if str not found.
isalnum() Returns true if the string has at least 1 character and all characters are alphanumeric and false otherwise.
isalpha() Returns true if the string has at least 1 character and all characters are alphabetic and false otherwise.
isdigit() Returns true if the string contains only digits and false otherwise.
islower() Returns true if the string has at least 1 cased character and all cased characters are in lowercase and false otherwise.
isnumeric() Returns true if a Unicode string contains only numeric characters and false otherwise.
isspace() Returns true if the string contains only whitespace characters and false otherwise.
istitle() Returns true if the string is properly "title cased" and false otherwise.
isupper() Returns true if the string has at least one cased character and all cased characters are in uppercase and false otherwise.
join(seq) Merges (concatenates) the string representations of elements in sequence seq into a string, with separator string.
len(string) Returns the length of the string
ljust(width[, fillchar]) Returns a space-padded string with the original string left-justified to a total of width columns.
lower() Converts all uppercase letters in a string to lowercase.
lstrip() Removes all leading whitespace in string.
maketrans() Returns a translation table to be used in the translate function.
max(str) Returns the max alphabetical character from the string str.
min(str) Returns the min alphabetical character from the string str.
replace(old, new [, max]) Replaces all occurrences of old in a string with new or at most max occurrences if max gave.
rfind(str, beg=0,end=len(string)) Same as find(), but search backwards in string.
rindex( str, beg=0, end=len(string)) Same as index(), but search backwards in string.
rjust(width,[, fillchar]) Returns a space-padded string with the original string right-justified to a total of width columns.
rstrip() Removes all trailing whitespace of string.
split(str="", num=string.count(str)) Splits string according to delimiter str (space if not provided) and returns a list of substrings; split into at most num substrings if given.
splitlines( num=string.count('\n')) Splits string at all (or num) NEWLINEs and returns a list of each line with NEWLINEs removed.p>
startswith(str, beg=0,end=len(string)) Determines if a string or a substring of string (if starting index beg and ending index end are given) starts with substring str; returns true if so and false otherwise.
strip([chars]) Performs both lstrip() and rstrip() on string.
swapcase() Inverts case for all letters in string.
title() Returns "title cased" version of the string, that is, all words begin with uppercase and the rest are lowercase.
translate(table, deletechars="") Translates string according to translation table str(256 chars), removing those in the del string.
upper() Converts lowercase letters in a string to uppercase.
zfill (width) Returns original string left padded with zeros to a total of width characters; intended for numbers, zfill() retains any sign given (less one zero).
isdecimal() Returns true if a Unicode string contains only decimal characters and false otherwise.