


R
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
Search for a command to run...
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
No comments yet. Be the first to comment.
In this series, we will discuss about various techniques and libraries that we can use for transcribing an audio file.
Before we start discussing the conversion of these two audio file formats. Let's talk about what are these formats and what is the difference and when to use these formats. WAV vs MP3 WAV and MP3 are file formats for storing digital audio. These...
Post #2 in the Complete Prompt Engineering Series Welcome back! In What is Prompt Engineering? A Complete Introduction, you learned what prompt engineering is and why it matters. Now we're going deeper: understanding the engine under the hood. You do...

Welcome to the future of human-AI collaboration. If you're reading this in 2024-2025, you're witnessing a fundamental shift in how humans interact with machines—and prompt engineering is your passport to this new world. The Definition: What Exactly I...
In this post, we’ll walk through the anatomy of a great prompt, illustrate every step with vivid examples, and even peek under the hood to see what happens technically when you hit “send.” By the end, you’ll be able to craft prompts that unlock the f...
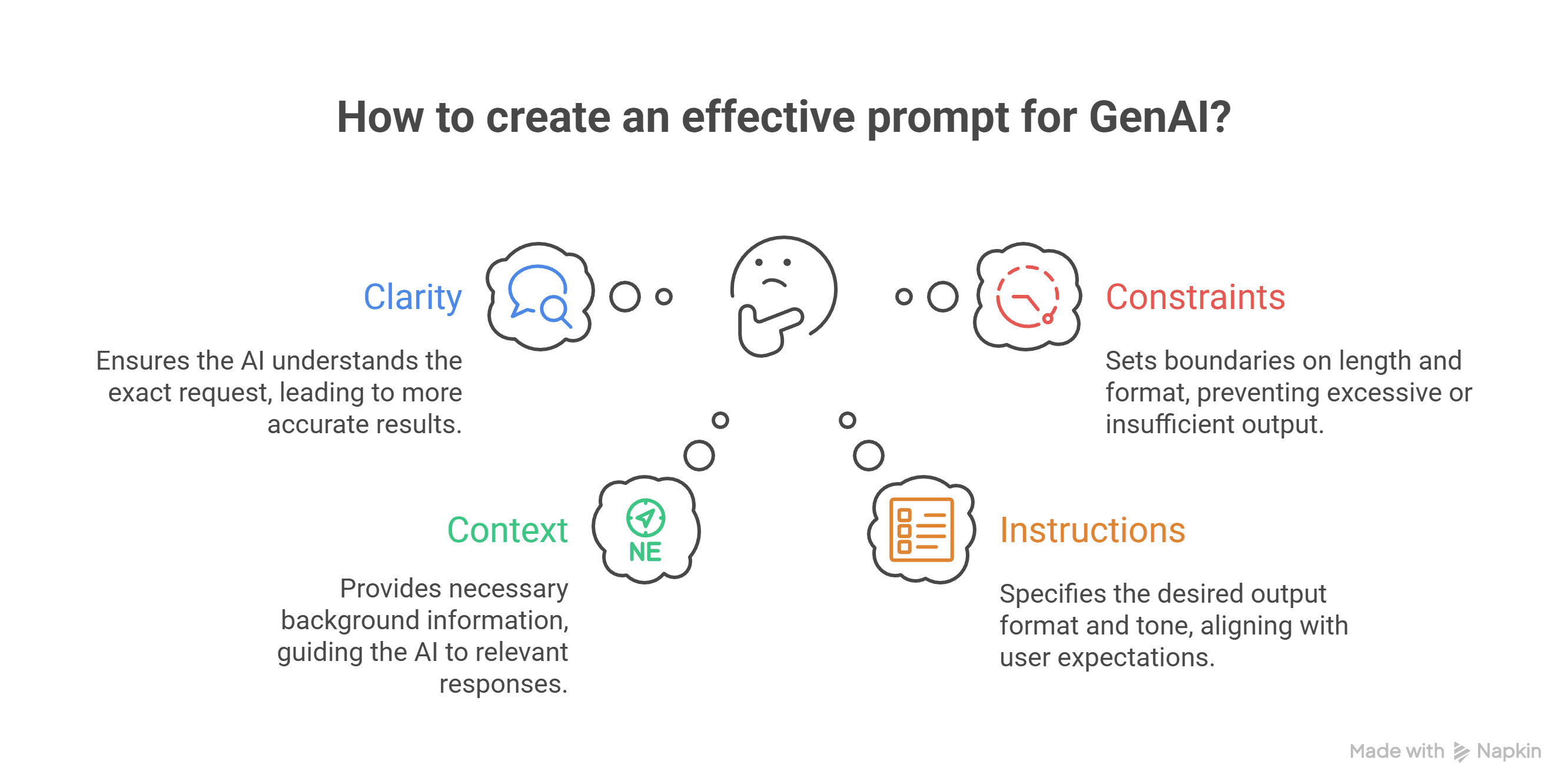
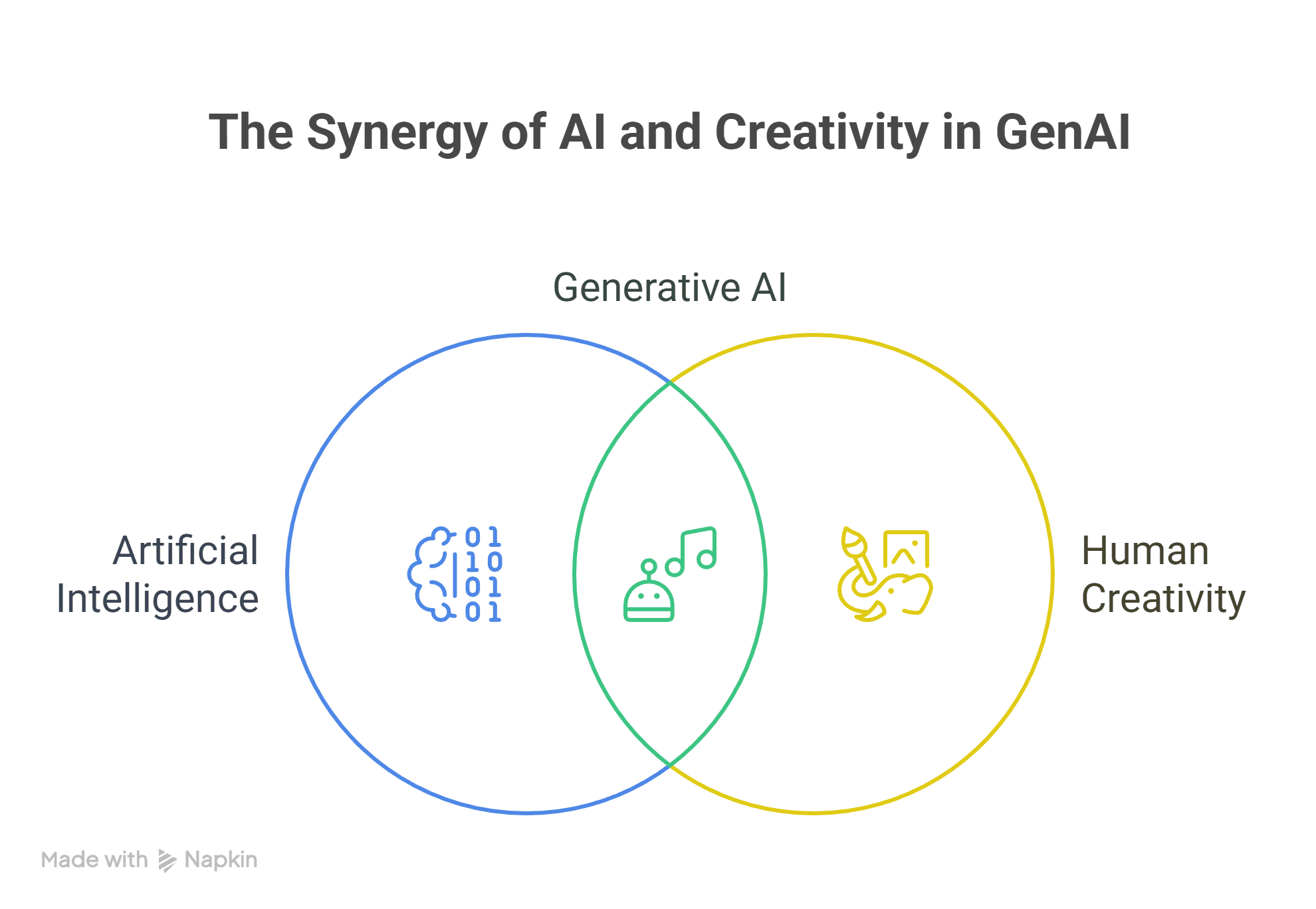
What is GenAI and Why Does Prompting Matter? If you’ve ever wondered how people interact with AI tools, or why some folks seem to get exactly what they want from tools like ChatGPT while others receive confusing or generic responses, this article is ...
Let’s be honest—being a developer isn’t just about writing code. It’s about solving problems, dealing with burnout, handling meetings, chasing deadlines, and finding time to learn, debug, and ship. But in the middle of this chaos, one simple habit ca...

Are you struggling with writing subtitles for your videos? Well, this is a very common issue. So in this article, we will discuss how to create a subtitle file from a video or audio file. Before starting with it there are few things that we need to set up.
moviepy library you can use the following pip command.pip install moviepy
Google cloud speech to text API please follow the instructions given in Using the Speech-to-Text API with Python Once it's done we can proceed further by discussing every step one by one.
the overall goal of this process is to generate an audio file. So that we can use it for the transcription process. If you already have an audio file you can skip this step and proceed further.
we will be using the moviepy library, let's check the below code.
from moviepy.editor import *
mp4_file = r'videosample\video.mp4'
mp3_file = r'videosample\video.mp3'
videoclip = VideoFileClip(mp4_file)
audioclip = videoclip.audio
audioclip.write_audiofile(mp3_file)
audioclip.close()
videoclip.close()
as you can see it's pretty straightforward code that takes two inputs and calls a function VideoFileClip with video file as an argument, it returns the audio file. And then we are writing the audio files into the audio file path.
Once you convert the video file into an audio file. it produces a file with an mp3 file format. Now we need to convert it to wav file format. You must be thinking about why we are re-formatting it. If you need to know more about it, please read this Mp3 to Wav File Conversion using Python article. it will teach you about the conversion as well as why we need to convert it. But if you already have a wav file with you then we don't need to convert it.
we will split the audio file into 15 secs audio chunks and we will save it in multiple files.
To split the file, we will use the FFmpeg command. for example,
FFmpeg -i audiosample\file1.wav -f segment -segment_time 15 -ac 1 -c copy audiosample\parts\ut%09d.wav
we can do this using python and with multiple files as well. Please check the below code
#!/usr/bin/python
import os
from pathlib import Path
directory = r"path\to\audiofile\folder"
def segment(file,folder,org_path):
folder=str(folder)+"\\parts"
if not os.path.exists(folder):
os.system("mkdir "+folder)
parts=str(org_path)+"\\parts\\ut%09d.wav"
os.system("ffmpeg -i \""+str(file)+"\" -f segment -segment_time 15 -ac 1 -c copy \""+parts+"\"")
print(str(file)+" segmentation Done...")
def recur(folder_path):
p=Path(folder_path)
dirs=p.glob("*")
i=0
for folder in dirs:
if folder.is_dir():
print("Processing Folder- "+str(folder))
recur(folder)
else:
print("Segmenting File- "+str(folder))
i+=1
new_folder_path=str(folder_path).split("\\")[-2]+"\\"+str(folder_path).split("\\")[-1]
# print()
segment(folder,new_folder_path,folder_path)
if __name__ == "__main__":
recur(directory)
It will split the file into various chunks of files as shown below.

Now we have to transcribe all the chunks using Google Cloud Speech to Text API.
And create a .srt file from the response that we get from the API.
Let import all the libraries that we will use in this.
import os
from pathlib import Path
from google.cloud import speech_v1 as speech
Let's create a function to iterate through all the files in a directory and transcribe them all one by one.
def recur(folder_path):
p=Path(folder_path)
dirs=p.glob("*")
i=0
for folder in dirs:
folder_path_str=str(folder)
folder_details=folder_path_str.split("\\")
folder_len=len(folder_details)
if folder_details[folder_len-1]!="parts":
pass
else:
convert(folder,folder_path,folder_details[folder_len-2])
In the above function, we walked through each folder in the input directory and checked if we encounter any directory called parts then we are calling the convert function with folder path, parent directory path, and parent directory name.
Now let's create a convert function to transcribe and save it in the .srt file.
def convert(file,folder,pack):
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="api-key.json"
files = sorted(os.listdir(str(file)+'/'))
all_text = []
for f in files:
name = str(file)+'/' + f
print("Transcribing File- "+str(name))
with open(name, "rb") as audio_file:
content = audio_file.read()
try:
config = speech.RecognitionConfig(encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,language_code="en-US")
audio = speech.RecognitionAudio(content=content)
text =speech_to_text(config, audio)
all_text.append(text)
except Exception as e:
print(e)
text = "No Audio"
all_text.append(text)
transcript = ""
for i, t in enumerate(all_text):
total_seconds = i * 15
m, s = divmod(total_seconds, 60)
h, m = divmod(m, 60)
total_seconds_n = total_seconds + 15
m_n, s_n = divmod(total_seconds_n, 60)
h_n, m_n = divmod(m_n, 60)
transcript = transcript + "{}\n{:0>2d}:{:0>2d}:{:0>2d},000 --> {:0>2d}:{:0>2d}:{:0>2d},000\n {}\n\n".format(i+1,h, m, s,h_n, m_n, s_n, t)
print("Transcript completed- "+str(transcript))
transcript_file=str(folder)+"/"+str(pack)+".srt"
with open(transcript_file, "w") as f:
f.write(transcript)
In the above script, we have set up the configuration and audio content that is required for transcription collected the transcript, and saved it in a file.
Important lines of code
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="api-key.json"
speech_to_text function.config =speech.RecognitionConfig(encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,language_code="en-US")
audio = speech.RecognitionAudio(content=content)
text =speech_to_text(config, audio)
Now, We will create the speech_to_text function and call the API.
def speech_to_text(config, audio):
client = speech.SpeechClient()
operation = client.long_running_recognize(config=config, audio=audio)
response = operation.result(timeout=90)
text_res=print_sentences(response)
return text_res
created an object for the SpeechClient class and call the long_running_recognize method with config and audio parameter, that will call the google cloud speech to text API and it will call an in-house function print_sentences with the response and once it return the transcript it will return the data to convert function.
Now let's see what this print_sentences function does.
def print_sentences(response):
for result in response.results:
best_alternative = result.alternatives[0]
transcript = best_alternative.transcript
confidence = best_alternative.confidence
print("-" * 80)
print(f"Transcript: {transcript}")
print(f"Confidence: {confidence:.0%}")
return transcript
Here we are parsing the response and printing the transcript data and its accuracy and then returning the transcript data.
Finally, let's call the recur function from the main module which is a base function in our program.
if __name__ == "__main__":
directory = r"path\to\chunks\directory"
recur(directory)
If we execute our program the output will look something like this.
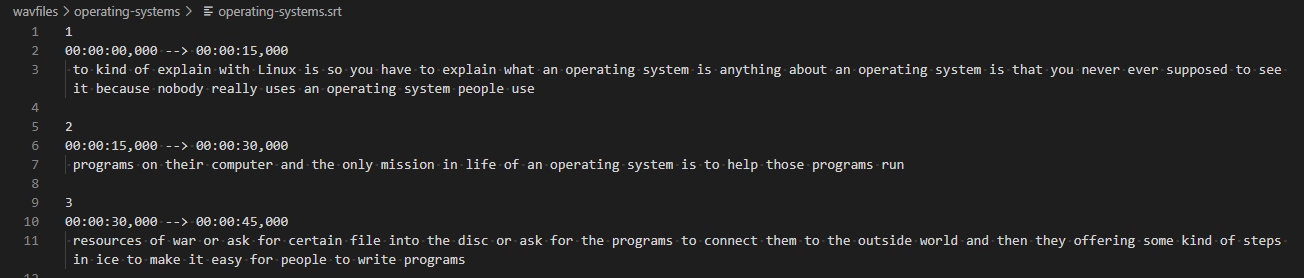
Now it is ready to use as a subtitle in your video.
GOOGLE_APPLICATION_CREDENTIALS Environment properly.Subscribe to my newsletter for more articles, and don't forget to give your opinion in the comment or to give this article a thumbs up. You can also support me by `Buying me a coffee.
Chao!!