

Crawl videos with selenium using python

R
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
Search for a command to run...
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
No comments yet. Be the first to comment.
Web scraping is the process of collecting and parsing raw data from the Web, and the Python community has come up with some pretty powerful web scraping tools. In this series we will learn those.
Many people struggle when they want some reference images or sample images. Images play a crucial role in creative professions like Blogging, Content Creating, photoshoot, Web & App prototyping, Presentation, etc. Some use it as a reference, Some use...
Post #2 in the Complete Prompt Engineering Series Welcome back! In What is Prompt Engineering? A Complete Introduction, you learned what prompt engineering is and why it matters. Now we're going deeper: understanding the engine under the hood. You do...

Welcome to the future of human-AI collaboration. If you're reading this in 2024-2025, you're witnessing a fundamental shift in how humans interact with machines—and prompt engineering is your passport to this new world. The Definition: What Exactly I...
In this post, we’ll walk through the anatomy of a great prompt, illustrate every step with vivid examples, and even peek under the hood to see what happens technically when you hit “send.” By the end, you’ll be able to craft prompts that unlock the f...
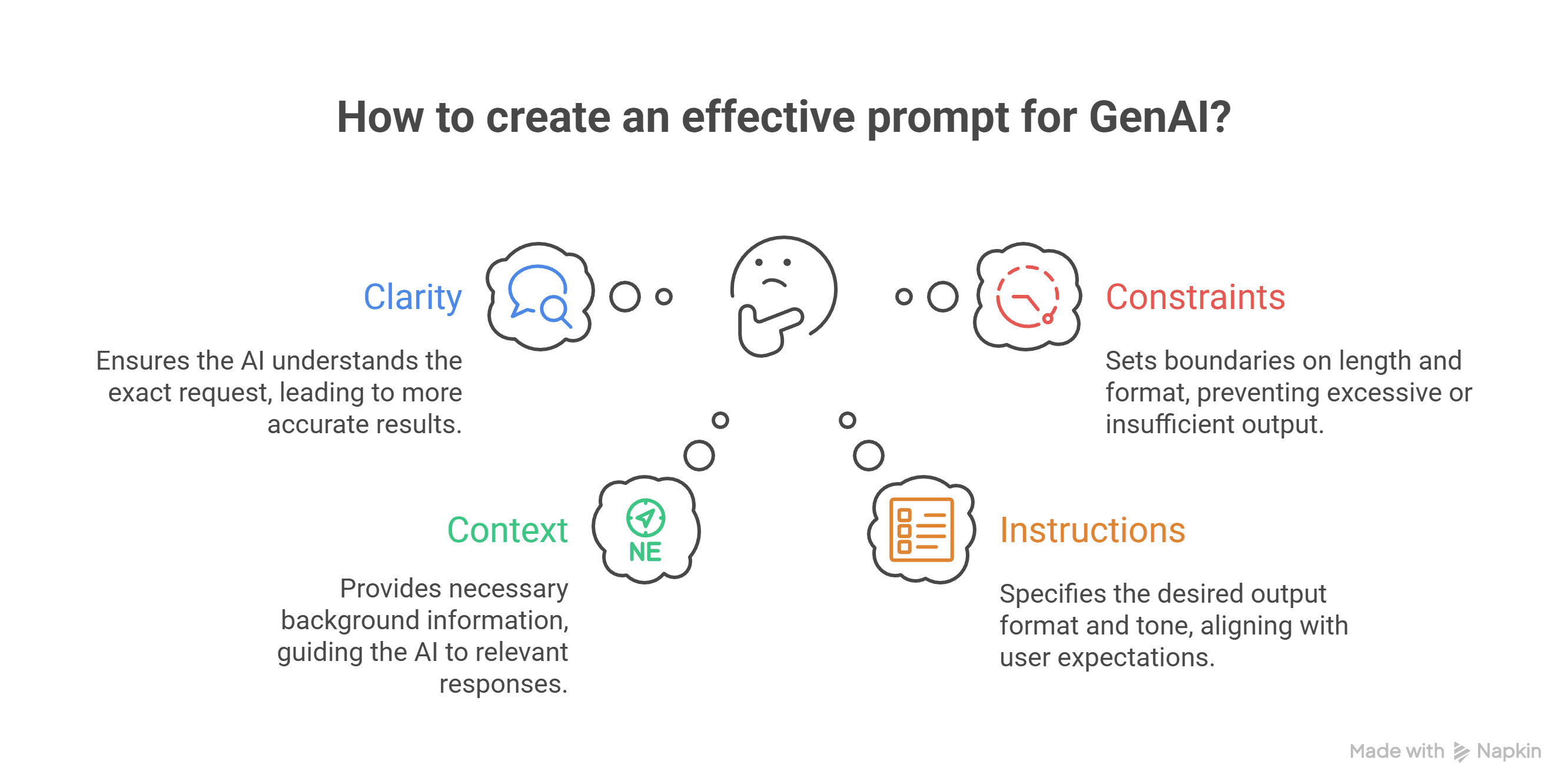
What is GenAI and Why Does Prompting Matter? If you’ve ever wondered how people interact with AI tools, or why some folks seem to get exactly what they want from tools like ChatGPT while others receive confusing or generic responses, this article is ...
Let’s be honest—being a developer isn’t just about writing code. It’s about solving problems, dealing with burnout, handling meetings, chasing deadlines, and finding time to learn, debug, and ship. But in the middle of this chaos, one simple habit ca...

After crawling the images from the web on my previous article Download raw images by keyword using python. Let's discuss downloading videos from the internet by keyword using python in this article. After doing some research, I came up with this site " Pexels" which provides free stock Vimeo videos.
Pexels also provide API for searching videos and photos but in this article, we will use a web scraping using selenium in python.
Let's understand the approach that we will be using in this article. So, if you check the Pexels website. it will look something similar to this
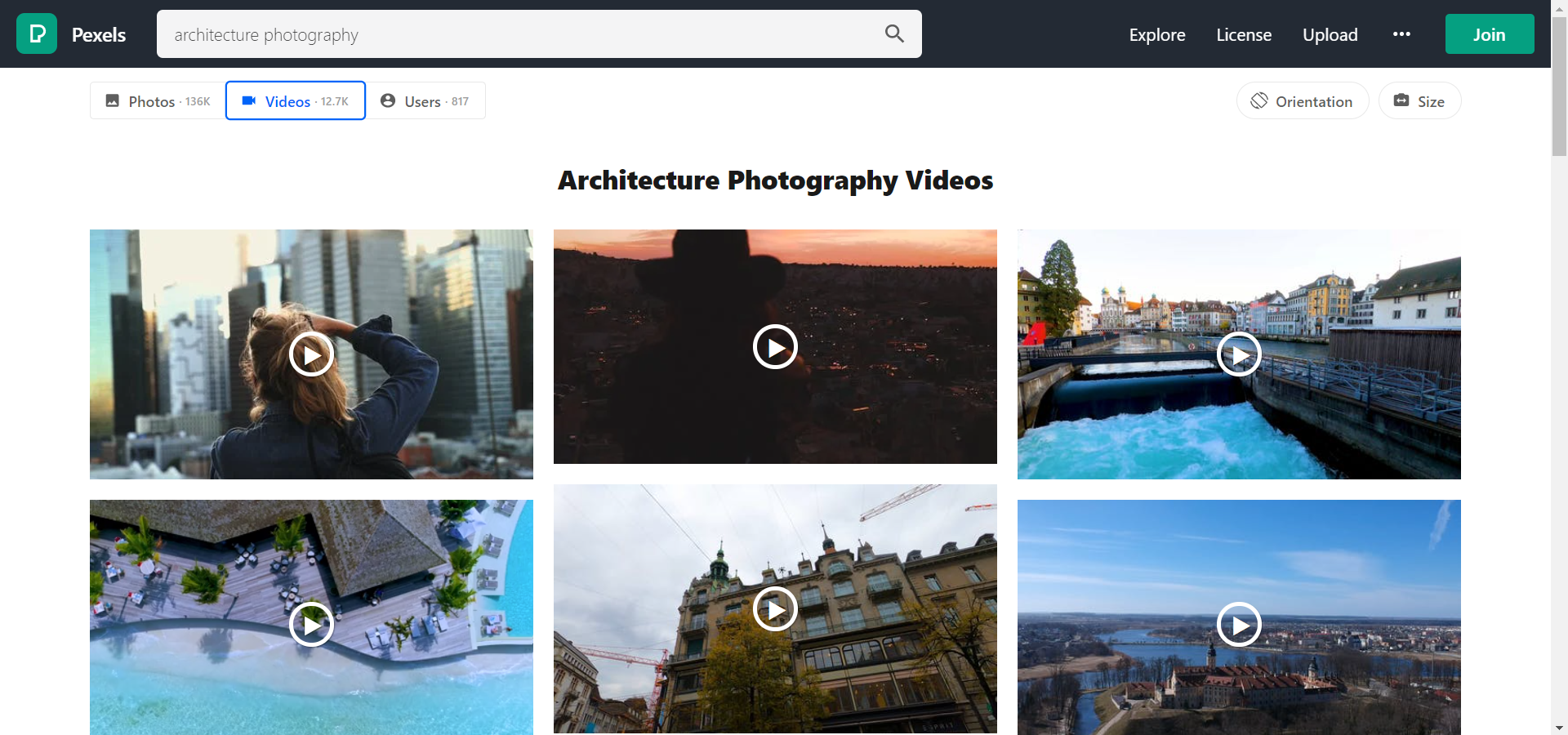
if you search anything in the search bar the URL of the page will also get updated like shown below

This will help us get the images with the keyword. if you see architecture%20photography is nothing but a keyword with URL encoding i.e architecture photography.
now let's check the structure of the website, its element, and video tags. So press F12 or right-click and click on inspect element. it will open up the browser console and check the element tab you will find the HTML structure and there scroll a bit and search for a div with the search__grid class. if you expand that div you will find the structure like this.

Now if you see there is a Video tag with a class called photo-item__video. and inside this tag, you will find the Source tag with type video/mp4. So our goal is to extract the src value of these source tags.
Once we get the URLs we have to transform them into Vimeo URL so that we can download them using vimeo_downloader library in python.
for example, in the above figure, the src contains this URL
https://player.vimeo.com/external/468162983.sd.mp4?s=1f9c036c702fec20f2abb2ae12d3b765ac7afd39&profile_id=139&oauth2_token_id=57447761
we have to grab the id 468162983 from it and generate a new Vimeo Link like this
https://player.vimeo.com/video/468162983
if you check the above link in your browser it will look something like this

Once we transform the URL we will save it along with the keyword name in an excel sheet. Similarly, we have to grab all the video URL from the page one by one and save it in excel. But keep this in mind, we can't grab all the URLs at once because the website has Lazy loading which means it loads a certain number of posts each time when we scroll the page till 60-70%. that means we have to write a script in such a way it will keep scrolling the page for a certain amount of time. once scrolling is done we have to grab all the video URLs from the page.
Let's code step by step. First, We will import all the required libraries and learn why we have used them.
#importing required Libraries
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
from vimeo_downloader import Vimeo
import timeit
import urllib
| Browser | DOWNLOAD LOCATION |
| Firefox | https://github.com/mozilla/geckodriver/releases |
| Chrome | http://chromedriver.chromium.org/downloads |
| Internet Explorer | https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver |
| Microsoft Edge | https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ |
urllib.parse.quote & urllib.parse.unquote module to encode/decode the URL in a proper format.Now let's move forward and declare some variables.
#declaring variables
Output_file=r"<path to output directory>\video_urls.xlsx"
xls_content=[]
genres=['fashion portrait']
url='https://www.pexels.com/search/videos/'
path = r'<path to Chrome driver directory>\chromedriver.exe'
here replace <path to output directory> to the absolute path of the directory where you want to store the excel file and replace <path to Chrome driver directory> with the absolute path of the Chrome Driver that you have downloaded from the above table.
Now let's create a if name == "main" function to proceed further.
if __name__ =="__main__":
#setting web driver
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument("--test-type")
driver = webdriver.Chrome(options=options,executable_path = path)
# looping through each keyword
for genre in genres:
genre=urllib.parse.quote(genre)
loadpage(driver,genre)
driver.close()
xls_data = pd.DataFrame(xls_content)
xls_data.to_excel(Output_file, engine='xlsxwriter', index=False)
In the above block of code we performed these steps shown below:
driver of the chrome `web driver with some options.loadpage along with web driver objectdriver.close() statement.Now, let's check what is this loadpage function is written for.
#loading genre using webdriver
def loadpage(driver,genre):
driver.get(url+genre) #load the url
sleep(10) # wait for 10 secs so that website loads properly
# scrolling the page for 2 minutes
starttime = timeit.default_timer()
i=0
while i<=120:
driver.find_element_by_tag_name('body').send_keys(Keys.PAGE_DOWN)
sleep(0.5)
i= round(timeit.default_timer() - starttime)
# extract the images from the page
extractingImages(driver,genre)
In this function
driver.get(url+genre) and then waits for 10 secs so that the website gets loaded completely. we are sending keypress PAGE_DOWN to scroll the web page for at least 2 mins to load more videos on the page. As videos are getting loaded from the javascript on scroll. we need to programmatically scroll the page with a delay of 0.5 secs for 2 minutes.
starttime = timeit.default_timer()
i=0
while i<=120:
driver.find_element_by_tag_name('body').send_keys(Keys.PAGE_DOWN)
sleep(0.5)
i= round(timeit.default_timer() - starttime)
where starttime contains the time at which we started scrolling and we keep on scrolling until we get the difference of the current time and start time greater than 120 secs i.e 2 mins
then we call the extractingImages with driver and genre as arguments.
Let's define the function extractingImages and see how can we extract images.
def extractingImages(driver,genre):
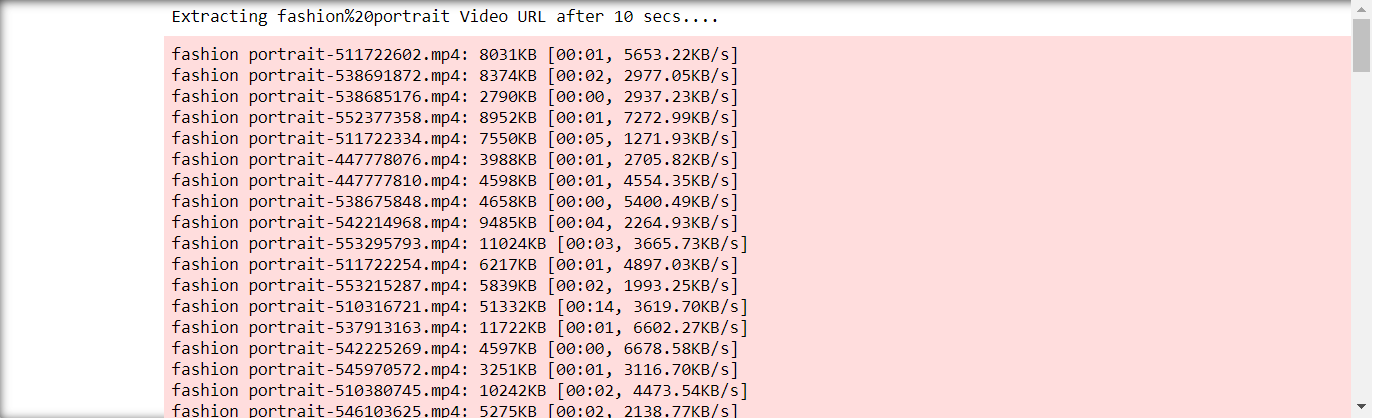
print(f"Extracting {genre} Video URL after 10 secs....")
sleep(10) # let it load the post properly
images = driver.find_elements_by_tag_name('source')
for image in images:
src=image.get_attribute('src')
vlink=src.split(".sd.mp4")[0].replace("https://player.vimeo.com/external/","https://player.vimeo.com/video/")
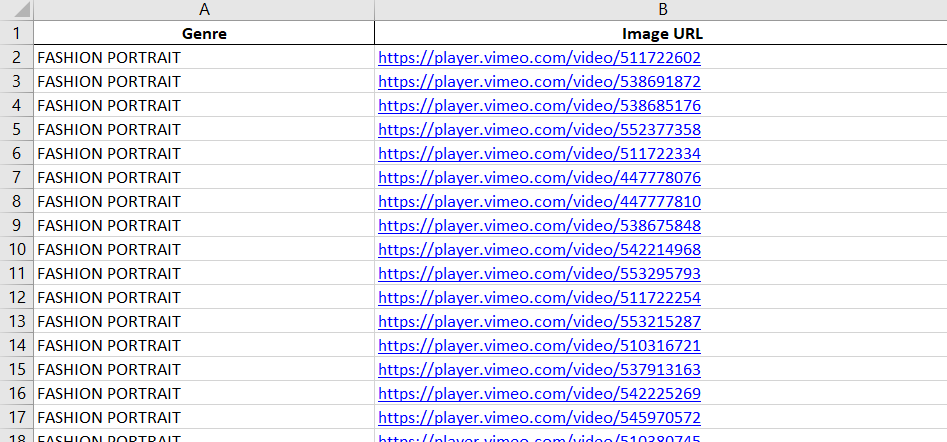
temp={}
temp['Genre']=(url+genre).split('/')[-1].replace("%20"," ").upper()
temp['Image URL']=vlink
xls_content.append(temp)
download_vimeo(vlink,url,genre)
source tag from the website content and looping all matched results to extract the src attribute value from it.download_vimeo by passing the video link, page URL, and genre to download the videos.Let's write the download_vimeo function and see how videos are getting downloaded from the links.
def download_vimeo(vimeo_url,embedded_on,genre):
v = Vimeo(vimeo_url, embedded_on)
stream = v.streams # List of available streams of different quality
# >> [Stream(240p), Stream(360p), Stream(540p), Stream(720p), Stream(1080p)]
filename=urllib.parse.unquote(genre)+"-"+vimeo_url.split('/')[-1]
# Download best stream
stream[-1].download(download_directory = 'video', filename = filename)
Vimeo class defined in vimeo_downloader package.v.streams and stored it in a variable called stream.filename='Food photography'+"-"+"511722602" i.e Food photography-511722602stream[-1] and calls the download function with arguments like folder path and filename. It will download the file Food photography-511722602.mp4 in folder name video under the current working directory. Like this, it will download all the files from the extracted video links.Now let's check the output of the script when we execute it.
video folder for the downloaded videos which will look something like this.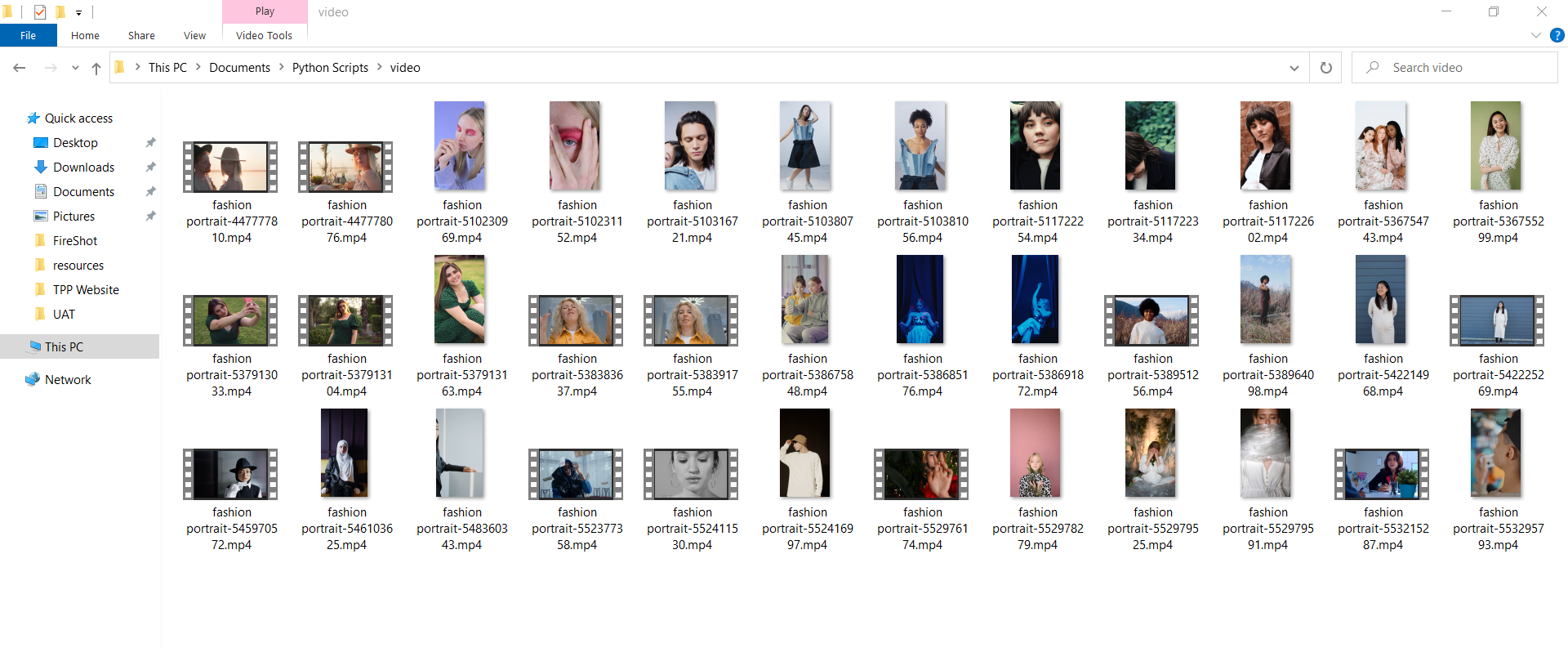
your downloaded file count will depend on the number of videos loaded on the webpage so you can increase or decrease the scrolling duration to control the file counts.
More the duration of scroll more videos it can download and more the time it will take.
you can download multiple types of videos all you have to do is just add the keywords in the genres list in the script.
scripts allows to opt for downloading the videos if you just want the list then just comment the download_vimeo function inside the extractImages function.
You can find the source code of this article from my Github Repository.
You can also download HD images using python. if you want to learn how then check my previous article Download RAW Images by keyword using Python. and if you want to learn more about How to do anything in python then just subscribe to my newsletter. you will get the notification automatically whenever I post a new article to my blog.
I hope you learned something new today from this article. if yes, then please give it a reaction and also give a star to my repository.
Chao!!
.