

Download RAW Images by keyword using Python

R
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
Search for a command to run...
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
I already tried this process in Gmail. when I use this process in Outlook with different domain. I got the log in issue like b'LOGIN failed.' can you please give me a solution
You have to use strong authentification now. Microsoft disabled the Basic Auth : https://techcommunity.microsoft.com/t5/exchange-team-blog/basic-authentication-deprecation-in-exchange-online-september/ba-p/3609437
In call_request() function, I think you mistakenly mentioned
headers = headers={'User-Agent': str(user_agent)}
I guess, it should be simply
headers = {'User-Agent': str(user_agent)}
Nice post.
thanks for pointing it out. will make the changes.
Web scraping is the process of collecting and parsing raw data from the Web, and the Python community has come up with some pretty powerful web scraping tools. In this series we will learn those.
After crawling the images from the web on my previous article Download raw images by keyword using python. Let's discuss downloading videos from the internet by keyword using python in this article. After doing some research, I came up with this sit...
Post #2 in the Complete Prompt Engineering Series Welcome back! In What is Prompt Engineering? A Complete Introduction, you learned what prompt engineering is and why it matters. Now we're going deeper: understanding the engine under the hood. You do...

Welcome to the future of human-AI collaboration. If you're reading this in 2024-2025, you're witnessing a fundamental shift in how humans interact with machines—and prompt engineering is your passport to this new world. The Definition: What Exactly I...
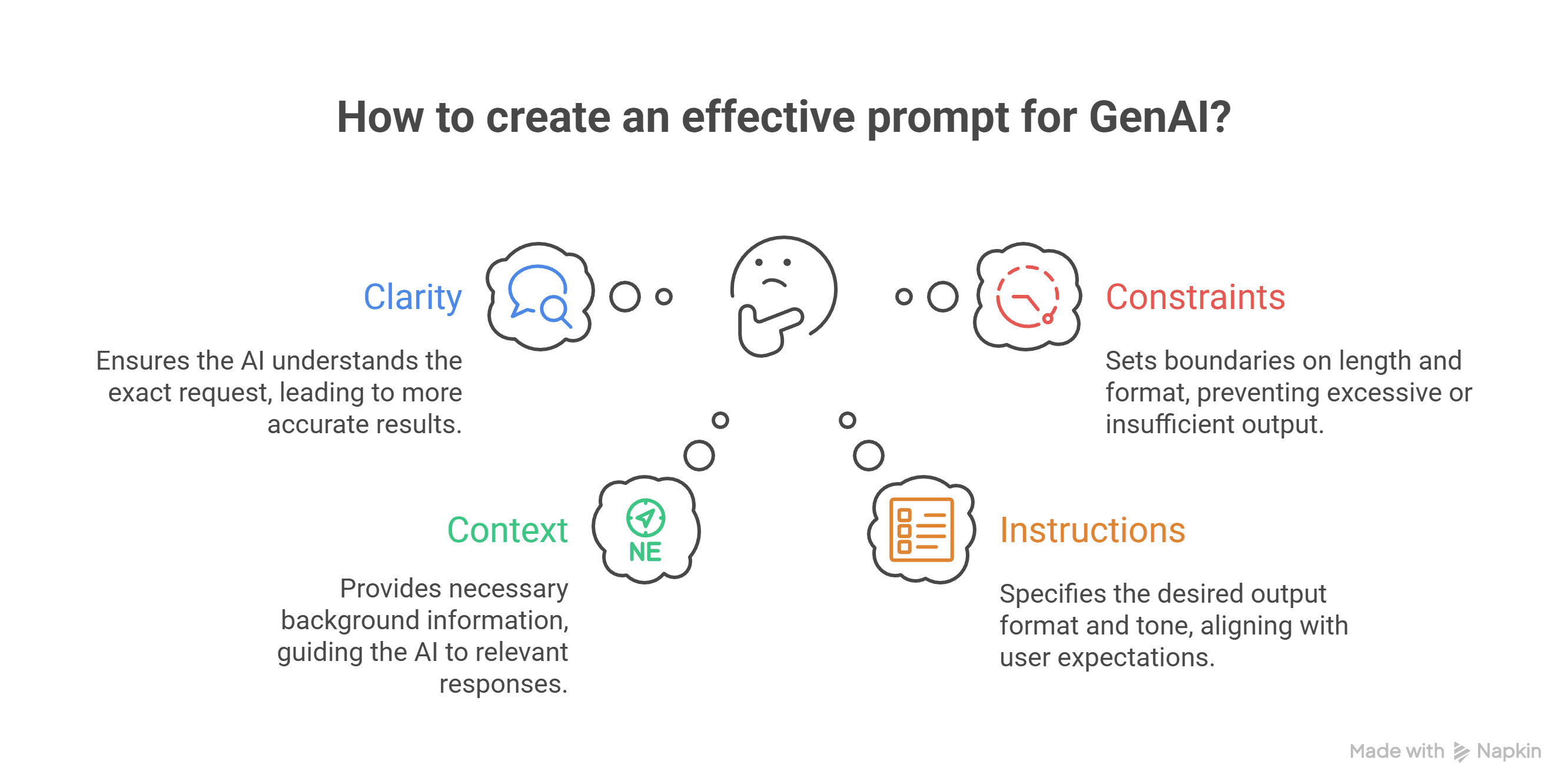
In this post, we’ll walk through the anatomy of a great prompt, illustrate every step with vivid examples, and even peek under the hood to see what happens technically when you hit “send.” By the end, you’ll be able to craft prompts that unlock the f...
What is GenAI and Why Does Prompting Matter? If you’ve ever wondered how people interact with AI tools, or why some folks seem to get exactly what they want from tools like ChatGPT while others receive confusing or generic responses, this article is ...
Let’s be honest—being a developer isn’t just about writing code. It’s about solving problems, dealing with burnout, handling meetings, chasing deadlines, and finding time to learn, debug, and ship. But in the middle of this chaos, one simple habit ca...

Many people struggle when they want some reference images or sample images. Images play a crucial role in creative professions like Blogging, Content Creating, photoshoot, Web & App prototyping, Presentation, etc. Some use it as a reference, Some use it as a sample showcase in their projects, presentations.
This article will make you learn how to crawl HD images by keyword using python scripting.
So, we will use Unsplash, the internet’s source of freely usable images. you can check their website and join their community if you like. We can do this in two ways.
Formula 1
You can register for a developer profile and create an app to use their APIs. but In this article, we will not discuss this method.
We will use something from scratch by understanding their request calls from the page. So let's get started with Formula 2.
Formula 2
we can use different libraries and ways to extract the images. for example, Beautiful Soup, Python Selenium, but for this article, we will use Requests. You can use any of them as per your choice the concept is the same.
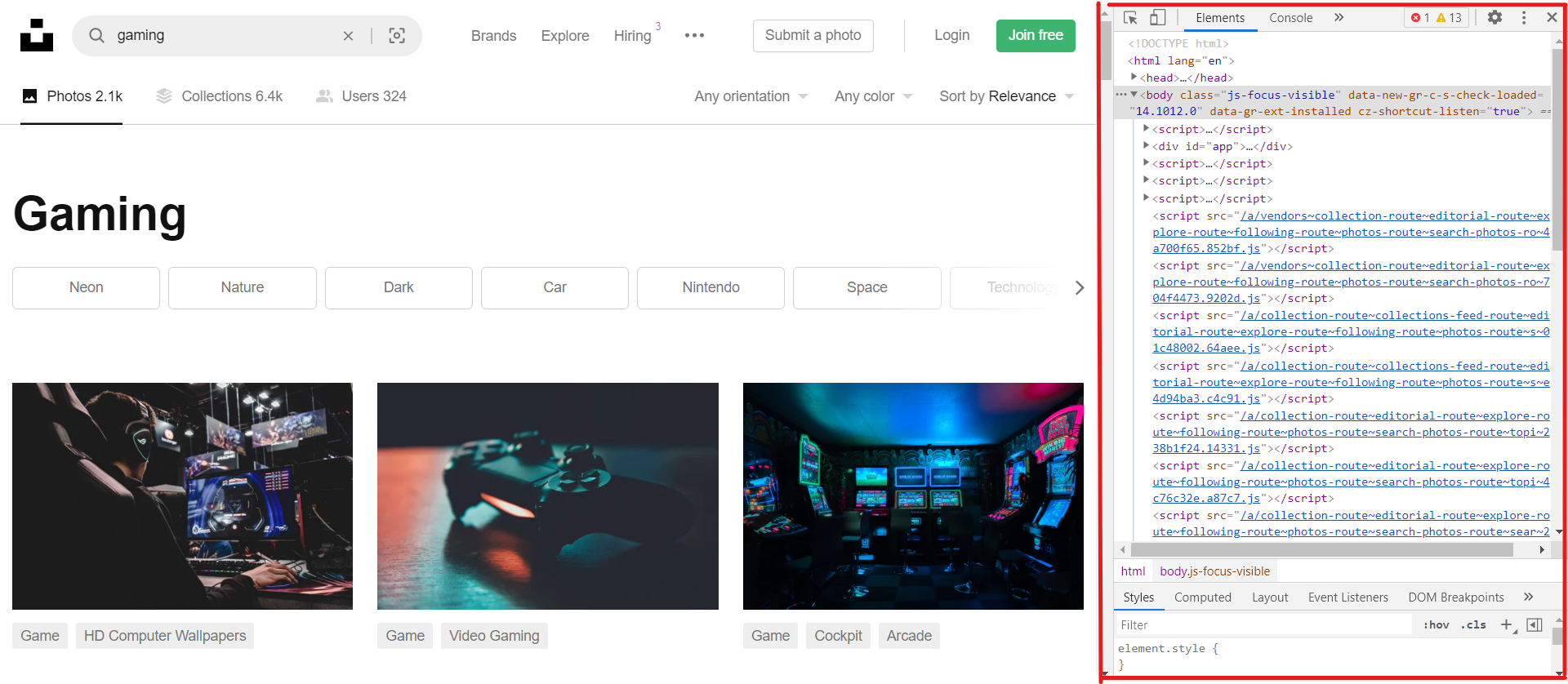
First, Let's understand from where we can get the images. Just go to Unsplash website and press F12 or right-click and click on inspect element. it will open up the browser console as shown below.
Now in the console click on the Network tab and again click on the Xhr option from the below menu. You will find out the request calls in the below section as shown in the below figure.
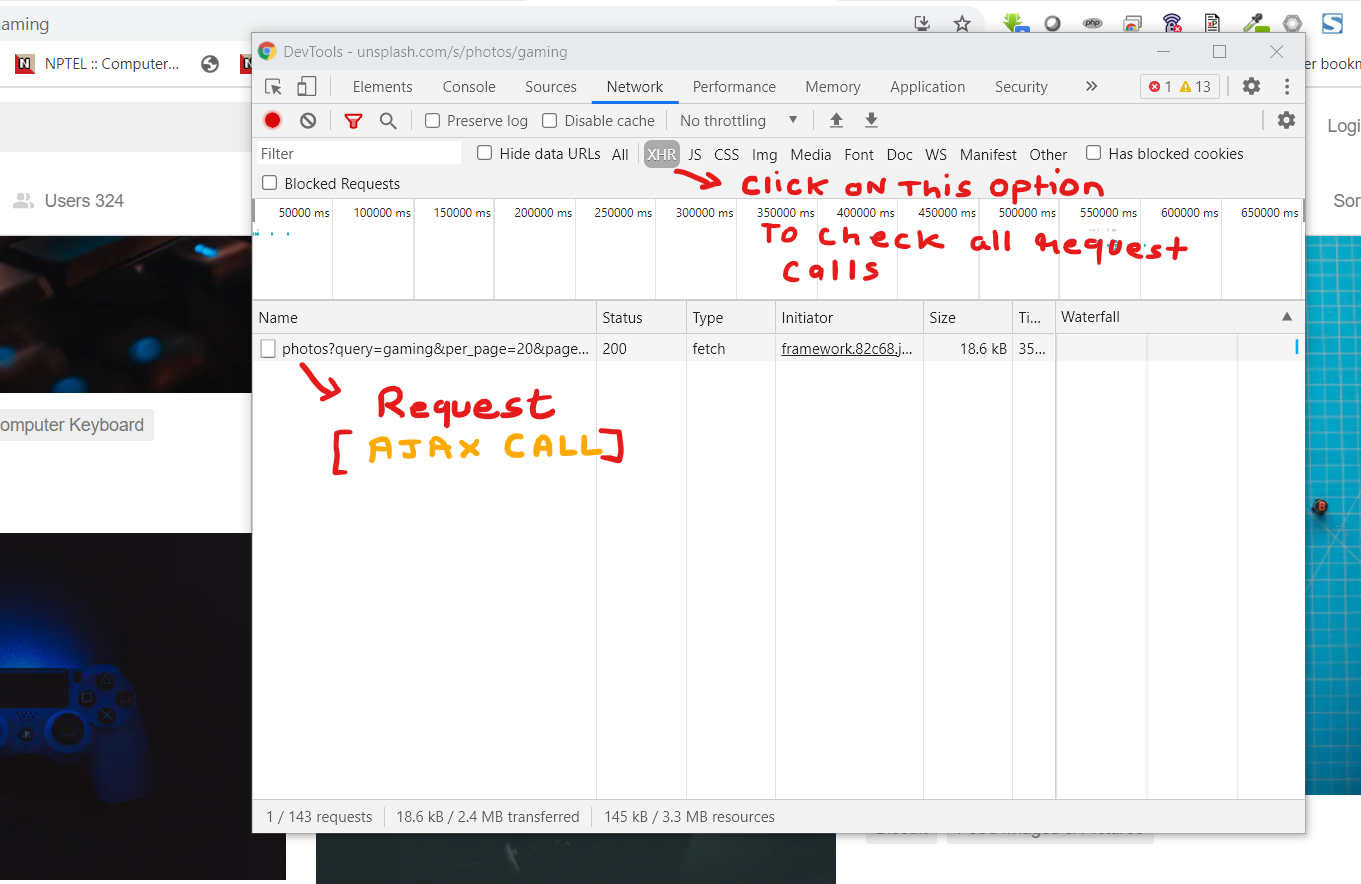
Now the question is how this can be useful for extracting the images by a keyword. So, the answer to this question is very simple. this website does the AJAX call or Xhr calls to load the images on scroll. So we are going to understand the payload and the request. if you check the header details of the request call you will find the endpoint and the payload. that looks something like this :
https://unsplash.com/napi/search/photos?query=marvel&per_page=20&page=2
here the endpoint is the URL, i.e
https://unsplash.com/napi/search/photos
and the rest of the string is called query string which is also known as input payload. here the payload is
{
"query":"marvel", # keyword
"per_page":20, # number of images to fetch
"page":2 # page number
}
if you hit this endpoint in your browser you will get the response in a JSON format and it will contain all the details related to the images along with the image URLs. it's your choice if you want to use other details you can extract those as well but in this article, we will only extract the raw URLs from the URLs element inside results. the response looks something like this:
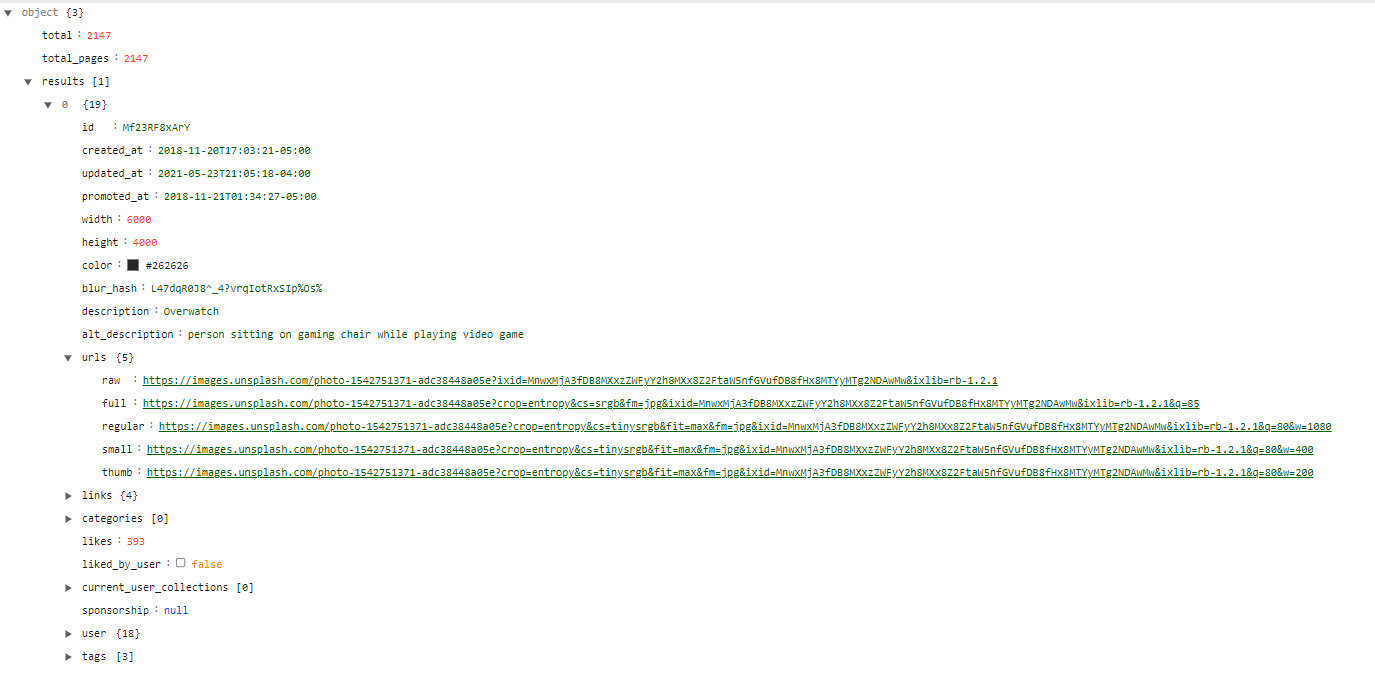
Now let's write some code to do the magic.
we need to request the endpoint with the payload and store the response in a variable and after that, we will extract the links and save them in an excel sheet. But first, let's import the libraries required for this task.
from typing import Union
import JSON
import pandas as pd
import requests
import urllib
import os
from fake_useragent import UserAgent
from requests.exceptions import HTTPError
It looks scary but let me break down what is the usage of these many libraries in this program.
urllib.parse.urlencode module to format the URL / endpoint in a proper format.import os - for using operating system dependent functionality like creating folders and files
from fake_useragent import UserAgent - grabs up-to-date useragent which will use be used in the header of the request.
Now let's create a function that will handle the calling of the request and sending back the response in the JSON format.
def call_request(url) -> Union[HTTPError, dict]:
user_agent = UserAgent()
headers={'User-Agent': str(user_agent)}
response = requests.get(url, headers=headers)
try:
response.raise_for_status()
except requests.exceptions.HTTPError as e:
return e
return response.json()
call_request which takes URL as an input and returns either HTTPError or a dictionary as a response.call_request function we are requesting the URL with the header and if it throws an error we are returning the error else returning the response in JSON.Let's call the function with the URL and extract the images from the response. So, for the payload let's search for 10 images of food photography and save the links along with the keyword name in an excel sheet.
if __name__== "__main__":
genre="food photography"
per_page=10
page=1
parameter={"query":genre,"per_page":per_page,"page":page}
query= urllib.parse.urlencode(parameter)
url=f"https://unsplash.com/napi/search/photos?{query}"
response=call_request(url)
image_list=[]
if len(response['results'])>0:
for i in range(len(response['results'])):
temp={ "Genre":genre, "link":response['results'][i]['urls']['raw']}
image_list.append(temp)
xls_data = pd.DataFrame(image_list)
xls_data.to_excel("image_list.xlsx", engine='xlsxwriter', index=False)
genre, per_page, page to store the basic details of the payload that we are going to use in the request. it is totally optional you can also put these in the payload itself.urllib.parse.urlencode module.Once it gets saved into the excel sheet it will look something like this:

Now the question arises this article was about downloading the images, So where are my images? I want it in my drive I don't want any links. Well, have some patience we have just started.
Let's now talk about how do we save it or download it from those links.
To download those images, we need to add few lines of codes here and there in our main block.
if __name__== "__main__":
genre="food photography"
per_page=10
page=1
image_folder_path= os.getcwd()+"\images"
if not os.path.isdir(image_folder_path):
os.mkdir(image_folder_path)
parameter={"query":genre,"per_page":per_page,"page":page}
query= urllib.parse.urlencode(parameter)
url=f"https://unsplash.com/napi/search/photos?{query}"
response=call_request(url)
image_list=[]
if len(response['results'])>0:
for i in range(len(response['results'])):
filename = response['results'][i]['urls']['raw'].split('/')[-1].split('?')[0]+".jpg"
folder_path=os.path.join(image_folder_path,genre)
if not os.path.isdir(folder_path):
os.mkdir(folder_path)
filepath=os.path.join(folder_path,filename)
r = requests.get(response['results'][i]['urls']['raw'], allow_redirects=True)
open(filepath.replace("\\", "/"), 'wb').write(r.content)
temp={ "Genre":genre, "link":response['results'][i]['urls']['raw']}
image_list.append(temp)
xls_data = pd.DataFrame(image_list)
xls_data.to_excel("image_list.xlsx", engine='xlsxwriter', index=False)
It's the same as the previous code but in extra it will download and save the images in our local file system. let's discuss those lines of code
image_folder_path= os.getcwd()+"\images"
if not os.path.isdir(image_folder_path):
os.mkdir(image_folder_path)
images under the current working directory. if the directory was not there at first to save all the images inside it. filename = response['results'][i]['urls']['raw'].split('/')[-1].split('?')[0]+".jpg"
folder_path=os.path.join(image_folder_path,genre)
if not os.path.isdir(folder_path):
os.mkdir(folder_path)
filepath=os.path.join(folder_path,filename)
r = requests.get(response['results'][i]['urls']['raw'], allow_redirects=True)
open(filepath.replace("\\", "/"), 'wb').write(r.content)
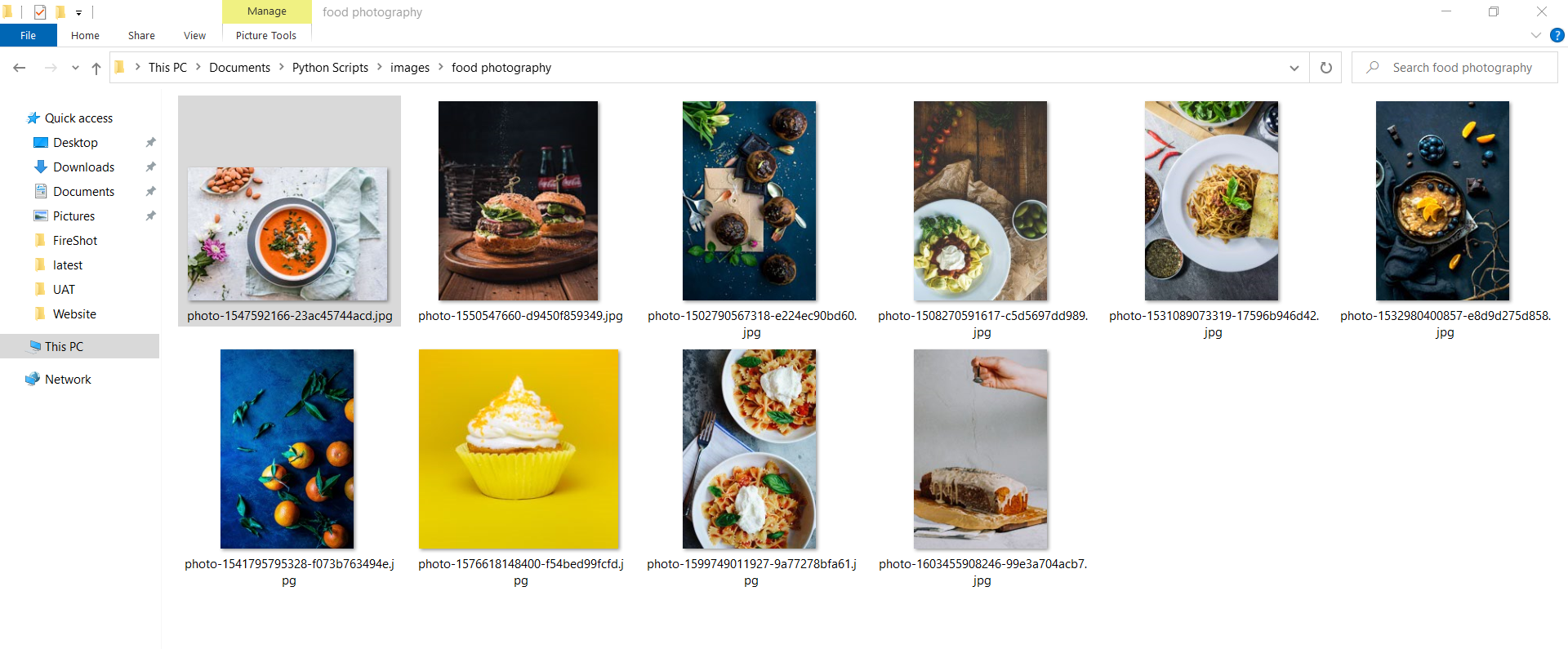
Now if you run the script it will create the directory with keyword name and store all the images inside that directory. for example,
keywords=['gaming','pokemon','PUBG']
for key in keywords:
genre =key
per_page=10
page=1
............
you can extract the image based on certain conditions such as ( most liked, by the user, etc. ) just study the response and data coming in it.
you can also download all the images till the last page. if you check the response there is an element that gives information about total pages.
you can get only 30 images per page even if you pass a value greater than 30.
You can clone or download the source code from my GitHub repository
Please show your love by starring the repository and hitting a like on this blog.
After reading this article you might be thinking can we do the same with videos as well? the answer is yes there are some websites that provide free stock videos. Subscribe to my newsletter if you wat to know more about it or if you want to read my other blogs whenever I add a new blog.
Chao!!