

Regular Expression in Python

R
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
Search for a command to run...
I am Developer, Artist and trying my luck on blogging as well. Well I am Ambitious, Passionate towards Learning, The Night Owl, And I Like challenges...
No comments yet. Be the first to comment.
In this series you will get the fundamentals of python programming, and it will help you write a clean and effective scripts in future.
How to Read Emails Using Python. As we know Python is being used widely across every domain. And I bet, every programmer had thought about building some kind of virtual assistance(let's call it VA) after watching "Iron Man Movie". In VA we add logic ...
Post #2 in the Complete Prompt Engineering Series Welcome back! In What is Prompt Engineering? A Complete Introduction, you learned what prompt engineering is and why it matters. Now we're going deeper: understanding the engine under the hood. You do...

Welcome to the future of human-AI collaboration. If you're reading this in 2024-2025, you're witnessing a fundamental shift in how humans interact with machines—and prompt engineering is your passport to this new world. The Definition: What Exactly I...
In this post, we’ll walk through the anatomy of a great prompt, illustrate every step with vivid examples, and even peek under the hood to see what happens technically when you hit “send.” By the end, you’ll be able to craft prompts that unlock the f...
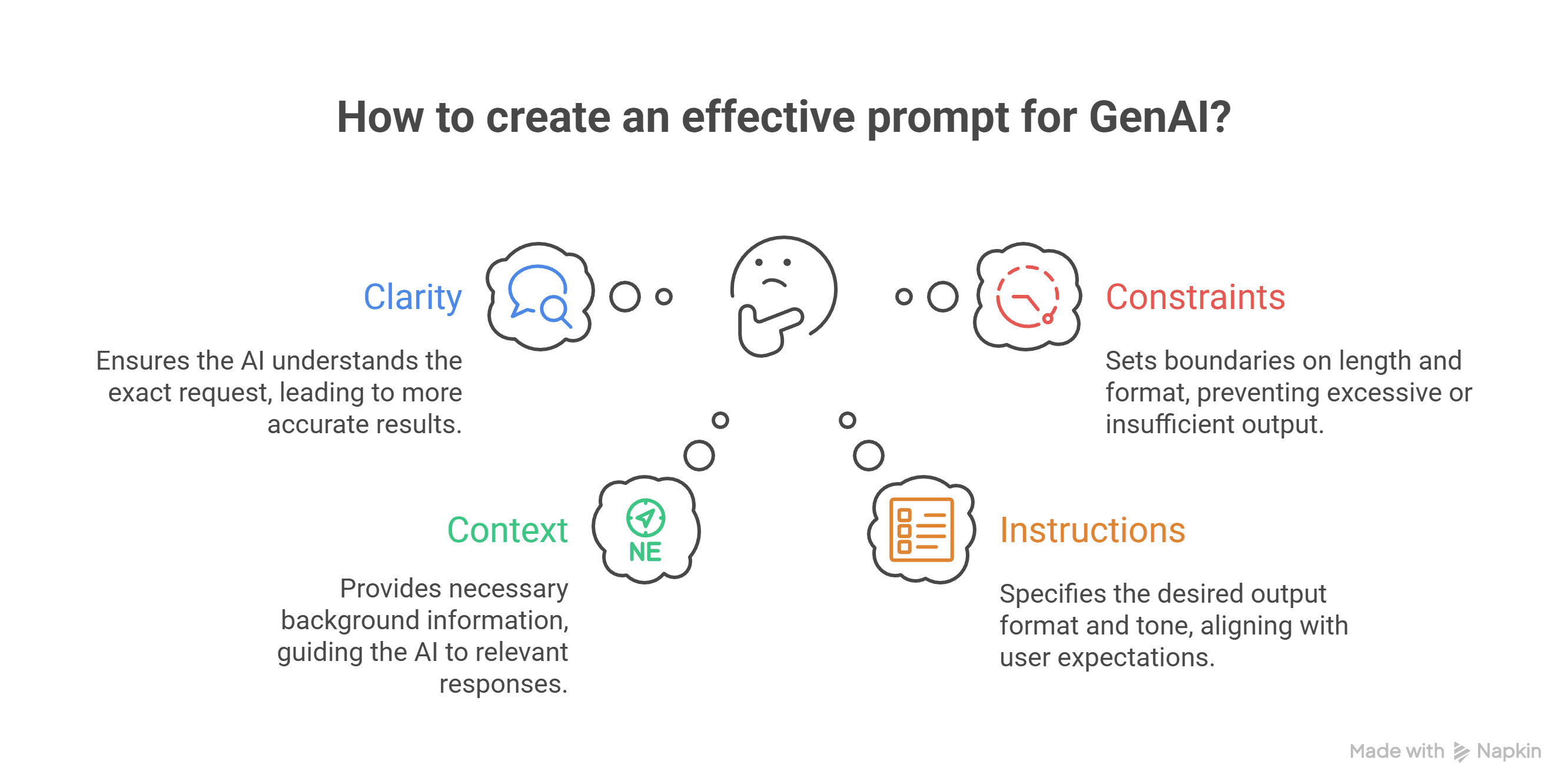
What is GenAI and Why Does Prompting Matter? If you’ve ever wondered how people interact with AI tools, or why some folks seem to get exactly what they want from tools like ChatGPT while others receive confusing or generic responses, this article is ...
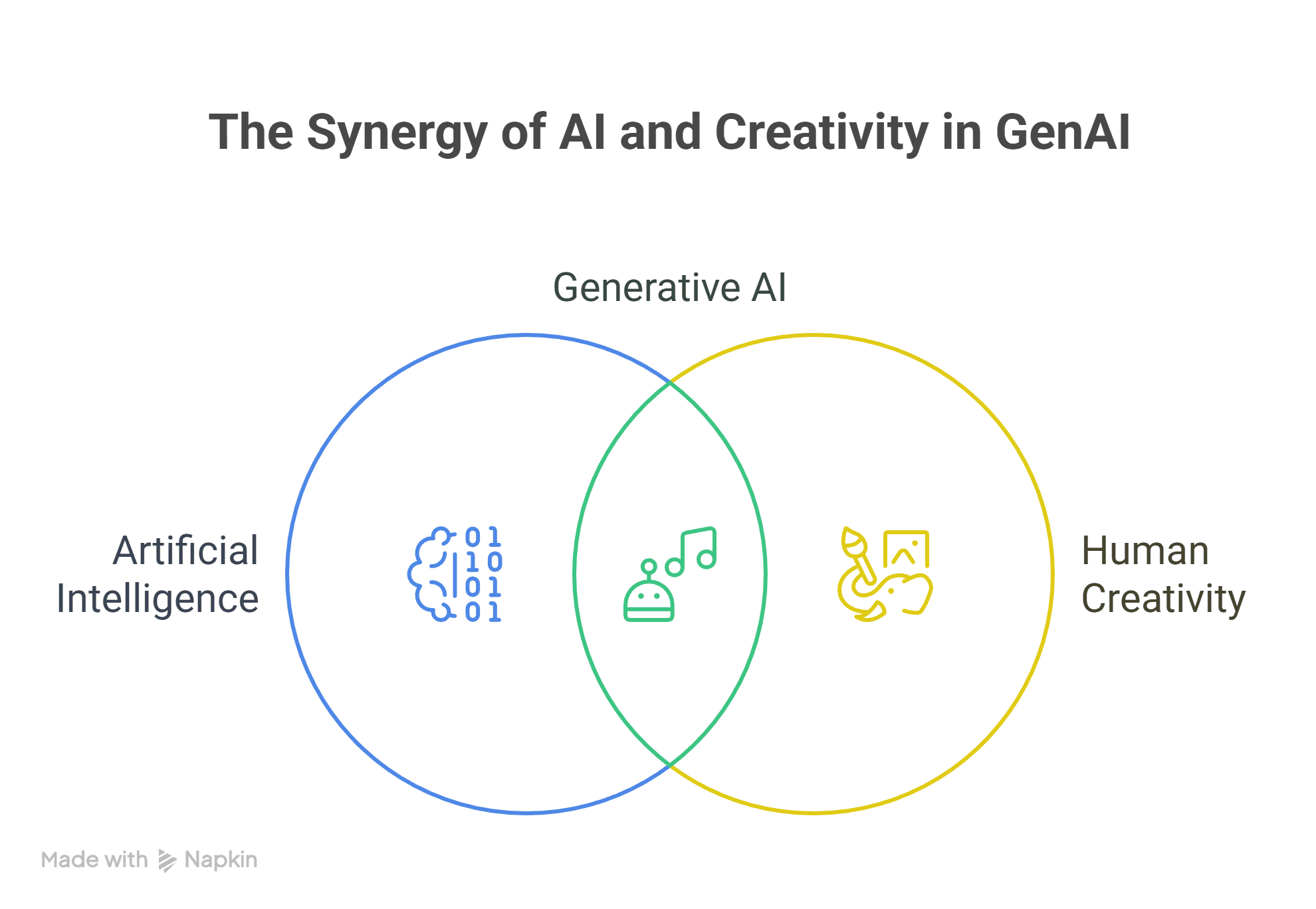
Let’s be honest—being a developer isn’t just about writing code. It’s about solving problems, dealing with burnout, handling meetings, chasing deadlines, and finding time to learn, debug, and ship. But in the middle of this chaos, one simple habit ca...

A Regular Expressions (RegEx) is a special sequence of characters that uses a search pattern to find a string or set of strings. It can detect the presence or absence of a text by matching with a particular pattern, and also can split a pattern into one or more sub-patterns. Python provides a re module that supports the use of regex in Python.
import re
s = 'GeeksforGeeks: A computer science portal for geeks'
match = re.search(r'portal', s)
print('Start Index:', match.start())
print('End Index:', match.end())
Start Index: 34
End Index: 40
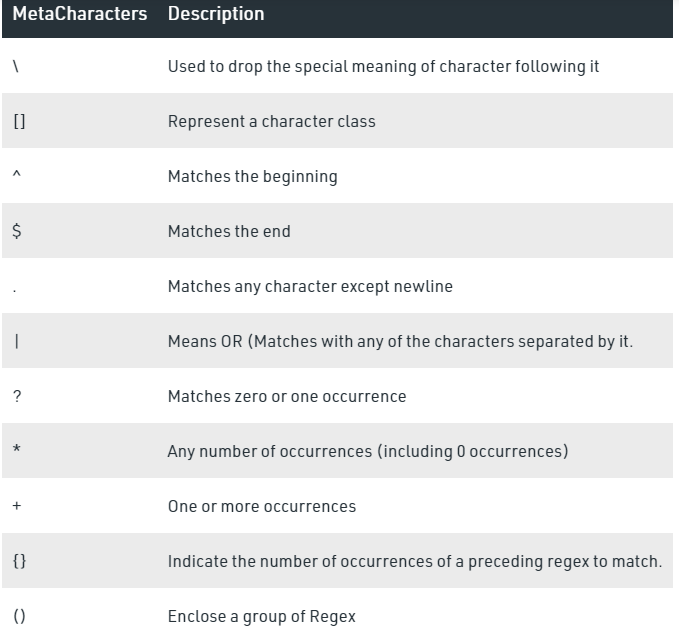
To understand the RE analogy, MetaCharacters are useful, important, and will be used in functions of module re. Below is the list of metacharacters.
#examples
import re
s = 'geeks.forgeeks'
# without using \
match = re.search(r'.', s)
print(match)
# using \
match = re.search(r'\.', s)
print(match)
<re.Match object; span=(0, 1), match='g'>
<re.Match object; span=(5, 6), match='.'>
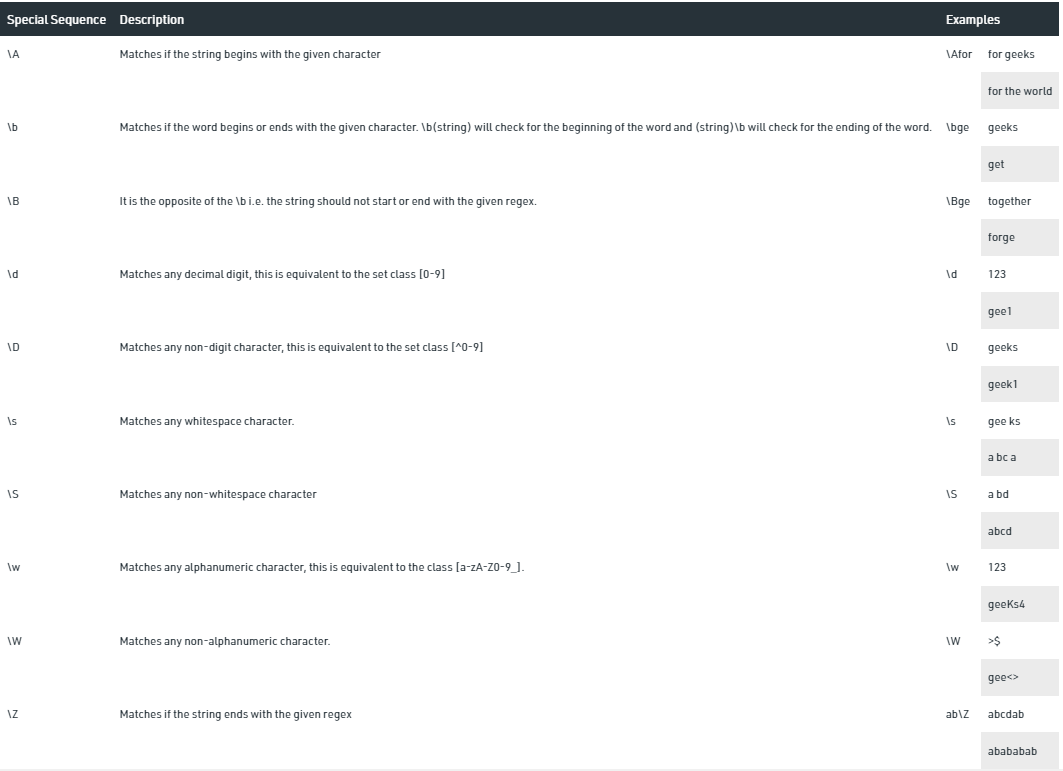
Special sequences do not match for the actual character in the string instead it tells the specific location in the search string where the match must occur. It makes it easier to write commonly used patterns.
Return all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found.
# A Python program to demonstrate working of
# findall()
import re
# A sample text string where regular expression
# is searched.
string = """Hello my Number is 123456789 and
my friend's number is 987654321"""
# A sample regular expression to find digits.
regex = '\d+'
match = re.findall(regex, string)
print(match)
# This example is contributed by Ayush Saluja.
['123456789', '987654321']
Regular expressions are compiled into pattern objects, which have methods for various operations such as searching for pattern matches or performing string substitutions.
# Module Regular Expression is imported
# using __import__().
import re
# compile() creates regular expression
# character class [a-e],
# which is equivalent to [abcde].
# class [abcde] will match with string with
# 'a', 'b', 'c', 'd', 'e'.
p = re.compile('[a-e]')
# findall() searches for the Regular Expression
# and return a list upon finding
print(p.findall("Aye, said Mr. Gibenson Stark"))
['e', 'a', 'd', 'b', 'e', 'a']
import re
# \w is equivalent to [a-zA-Z0-9_].
p = re.compile('\w')
print(p.findall("He said * in some_lang."))
# \w+ matches to group of alphanumeric character.
p = re.compile('\w+')
print(p.findall("I went to him at 11 A.M., he \
said *** in some_language."))
# \W matches to non alphanumeric characters.
p = re.compile('\W')
print(p.findall("he said *** in some_language."))
['H', 'e', 's', 'a', 'i', 'd', 'i', 'n', 's', 'o', 'm', 'e', '_', 'l', 'a', 'n', 'g']
['I', 'went', 'to', 'him', 'at', '11', 'A', 'M', 'he', 'said', 'in', 'some_language']
[' ', ' ', '*', '*', '*', ' ', ' ', '.']
Split string by the occurrences of a character or a pattern, upon finding that pattern, the remaining characters from the string are returned as part of the resulting list.
from re import split
# '\W+' denotes Non-Alphanumeric Characters
# or group of characters Upon finding ','
# or whitespace ' ', the split(), splits the
# string from that point
print(split('\W+', 'Words, words , Words'))
print(split('\W+', "Word's words Words"))
# Here ':', ' ' ,',' are not AlphaNumeric thus,
# the point where splitting occurs
print(split('\W+', 'On 12th Jan 2016, at 11:02 AM'))
# '\d+' denotes Numeric Characters or group of
# characters Splitting occurs at '12', '2016',
# '11', '02' only
print(split('\d+', 'On 12th Jan 2016, at 11:02 AM'))
['Words', 'words', 'Words']
['Word', 's', 'words', 'Words']
['On', '12th', 'Jan', '2016', 'at', '11', '02', 'AM']
['On ', 'th Jan ', ', at ', ':', ' AM']
The ‘sub’ in the function stands for SubString, a certain regular expression pattern is searched in the given string(3rd parameter), and upon finding the substring pattern is replaced by repl(2nd parameter), count checks and maintains the number of times this occurs.
import re
# Regular Expression pattern 'ub' matches the
# string at "Subject" and "Uber". As the CASE
# has been ignored, using Flag, 'ub' should
# match twice with the string Upon matching,
# 'ub' is replaced by '~*' in "Subject", and
# in "Uber", 'Ub' is replaced.
print(re.sub('ub', '~*', 'Subject has Uber booked already',
flags=re.IGNORECASE))
# Consider the Case Sensitivity, 'Ub' in
# "Uber", will not be reaplced.
print(re.sub('ub', '~*', 'Subject has Uber booked already'))
# As count has been given value 1, the maximum
# times replacement occurs is 1
print(re.sub('ub', '~*', 'Subject has Uber booked already',
count=1, flags=re.IGNORECASE))
# 'r' before the pattern denotes RE, \s is for
# start and end of a String.
print(re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam',
flags=re.IGNORECASE))
S~*ject has ~*er booked already
S~*ject has Uber booked already
S~*ject has Uber booked already
Baked Beans & Spam
his method either returns None (if the pattern doesn’t match), or a re.MatchObject that contains information about the matching part of the string. This method stops after the first match, so this is best suited for testing a regular expression more than extracting data.
# A Python program to demonstrate working of re.match().
import re
# Lets use a regular expression to match a date string
# in the form of Month name followed by day number
regex = r"([a-zA-Z]+) (\d+)"
match = re.search(regex, "I was born on June 24")
if match != None:
# We reach here when the expression "([a-zA-Z]+) (\d+)"
# matches the date string.
# This will print [14, 21), since it matches at index 14
# and ends at 21.
print ("Match at index %s, %s" % (match.start(), match.end()))
# We us group() method to get all the matches and
# captured groups. The groups contain the matched values.
# In particular:
# match.group(0) always returns the fully matched string
# match.group(1) match.group(2), ... return the capture
# groups in order from left to right in the input string
# match.group() is equivalent to match.group(0)
# So this will print "June 24"
print ("Full match: %s" % (match.group(0)))
# So this will print "June"
print ("Month: %s" % (match.group(1)))
# So this will print "24"
print ("Day: %s" % (match.group(2)))
else:
print ("The regex pattern does not match.")
Match at index 14, 21
Full match: June 24
Month: June
Day: 24
For more on Regular expressions